店舗と製品ラインは匿名化されていますが、そのデータセットは、ビジネスの洞察を得るための素晴らしい環境です。バスケット分析を用いて、データの準備方法、基本的な分析方法、そして追加的な洞察を得るための方法を説明します。
それでは実際にデータを見てみましょう。PivotBillionsの使い慣れたスプレッドシート形式で大量のデータを分析・操作します。データをインポートすると、50万行以上におよぶ膨大なデータを閲覧することができます。

列名をクリックすると列ごとの詳細がグラフで表示されます。全体的に整理されたデータですが、Product_Category_2とProduct_Category_3には多くの欠損値(NAs)が含まれています。それらは欠損値を持たないProduct_Category_1のサブカテゴリーのようですので、今のところは無視しておきましょう。

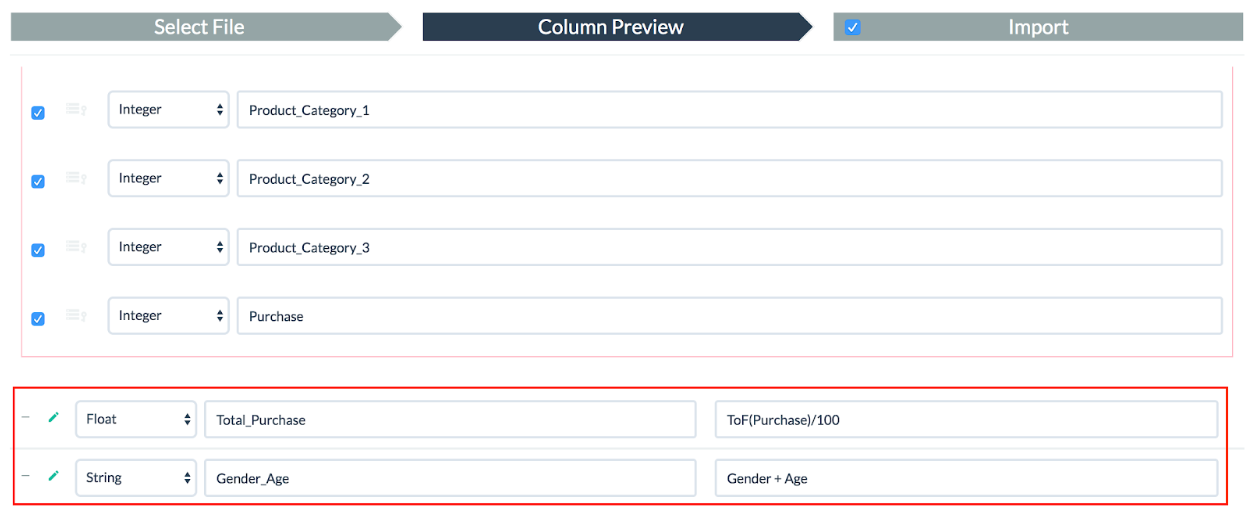
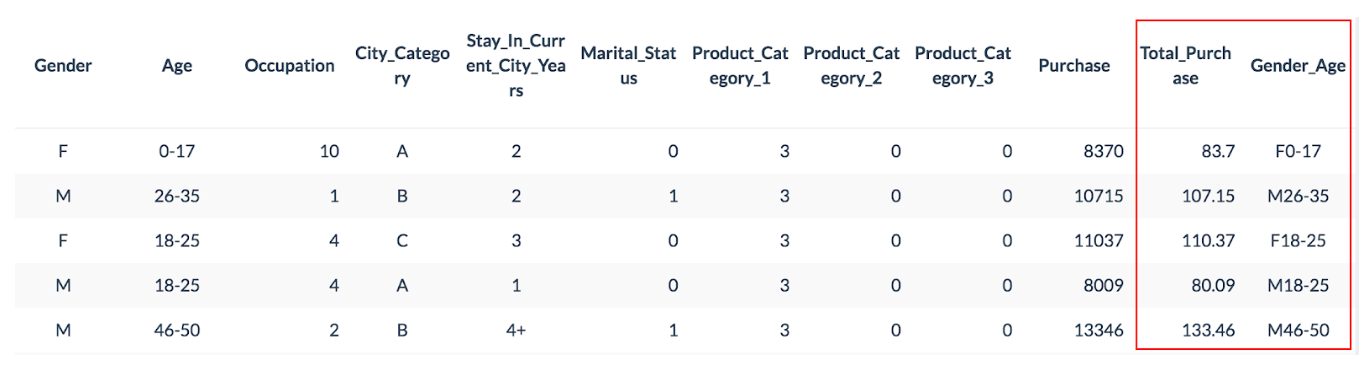
次に、分析用のデータを準備します。まず、小数点としてセントの単位まで表示するには、「Purchase」を100で割る必要があります。「Total_Purchase」というfloat列を定義し、「ToF(Purchase)/100」を設定します。
次に、棒グラフを作成するために、性別と年齢を組み合わせた列を作成しましょう。「Gender_Age」というstring列を定義し、以下のように「Gender + Age」を設定します。
PivotBillionsは、Excelと同様の操作でピボットテーブルを作成できるので、顧客のデモグラフィック、都市別売上高、職業、製品カテゴリーなどを簡単にチェックできます。以下の棒グラフは、製品カテゴリー別総購入額を示しています。
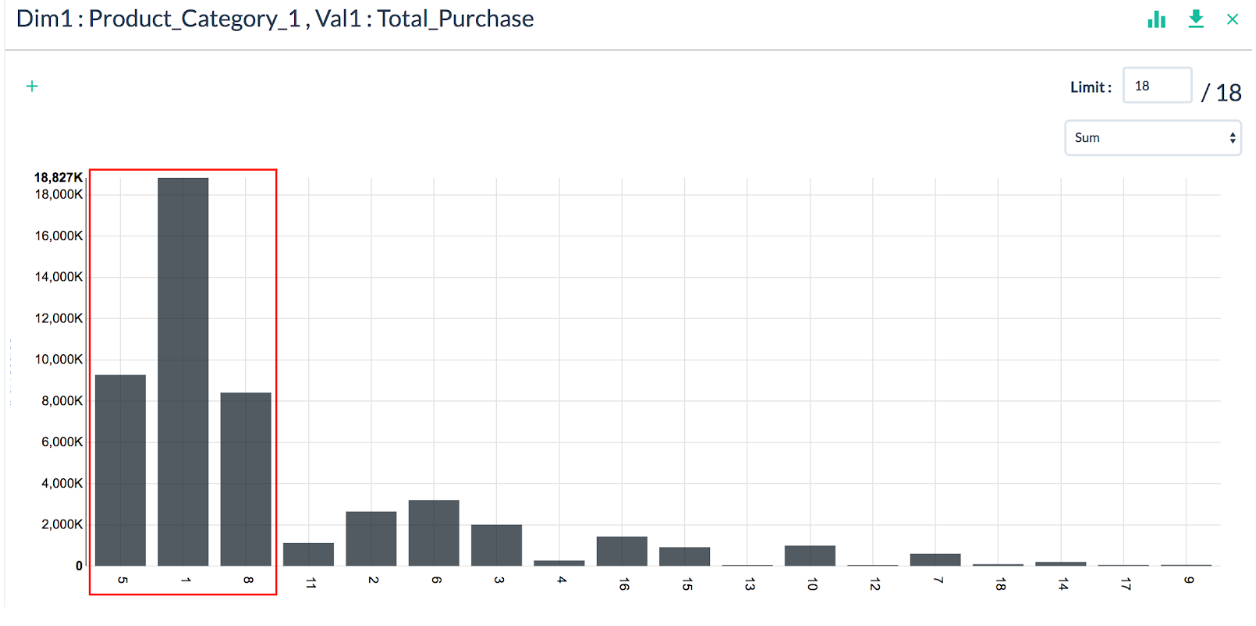
製品カテゴリー1が最も人気があることが分かります。製品カテゴリー1がこの小売チェーンの総購入額の約40%を占めていること、そして製品カテゴリー1、5、および8の合計購入額が全体の70%以上を占めていることが分かります。
次に、データをもう少し詳しく調べてみましょう。以下の棒グラフは、都市別総購入額と顧客のデモグラフィクスを示しています。

売り上げが最も多いのはB市で、いずれの都市も20代から30代の男性が多数を占めています。A市は35才以上の顧客の割合が比較的少なくなっています。これは、高齢者向けに販売をのばす機会がより多く残っていることも想定できます。各都市の詳細情報はこのデータセットには含まれていませんが、次のステップとして、そうした違いの理由を明らかにする必要があります。それにより、マーケティングチームと議論するためのより明確な洞察を得ることができます。
最後に、取引データに相関ルールマイニングを用いて商品間の相関を発見するバスケット分析を行いましょう。ここではPython言語のAprioriアルゴリズムを使用します。R言語もAprioriアルゴリズムを持っています。詳細については、以下のリンクで確認してください。
Apriori(Python) : http://rasbt.github.io/mlxtend/user_guide/frequent_patterns/apriori/#frequent-itemsets-via-apriori-algorithm
Apriori(R): https://www.rdocumentation.org/packages/arules/versions/1.6-3/topics/apriori
import pandas as pd from mlxtend.frequent_patterns import apriori,association_rules #Read the dataset data = pd.read_csv('./BlackFriday.csv') #Create the basket basket_data = data.loc[:,['User_ID','Product_ID']] count = basket_data.groupby(['User_ID', 'Product_ID']).size().reset_index(name='Count') basket = (count.groupby(['User_ID', 'Product_ID'])['Count'] .sum().unstack().reset_index().fillna(0) .set_index('User_ID')) #For this dataset, all values are either 1 or 0. Thus, you can apply this "basket" straight to apriori algorithm. #Set support >= 0.05 frequent_itemsets = apriori(basket, min_support=0.05, use_colnames=True) #Filter lift >= 1 rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1) #Sort ascending by lift rules.sort_values(by = 'lift',ascending=False)

Aprioriアルゴリズムの指標の意味を簡単に説明します。
- Support(支持度)は、アイテムがデータ内に出現する頻度を表します。
- Confidence(確信度)は、if(先行節)-then(帰結節)文が正しいと認められる頻度を表します。
- Lift(リフト)は、確信度が予想よりどの程度高いか、または低いかを表します。Liftが1.0より大きい場合、アイテム間の相関が予想よりも有意であることを意味します。Liftが大きいほど相関性が高いことを意味します。
リフト値が高い商品の組み合わせ(上位20)は以下のとおりです。

このバスケット分析では、特定の商品間で強力な組み合わせ購入のパターンが見つかりました。小売チェーンについて、より詳しく知ることができれば、今回の分析結果がさらなる分析や議論の基礎となり、戦略的な価格設定やプロモーションの機会をもたらすことができます。